VulnLLM-R: The Reasoning LLM That Finds Real Vulnerabilities
Written by the Rafter Team

Most vulnerability scanners spot patterns. VulnLLM-R reasons about exploits.
You've seen it before: a scanner flags a finding, but when you dig in, you can't figure out why it's exploitable. The code looks fine. The sanitization seems present. The guard appears to be there. Yet the scanner insists it's vulnerable.
That's because most security tools—even AI-powered ones—are pattern matchers in disguise. They look for dangerous APIs, missing checks, and known bad sinks. But real-world vulnerabilities don't follow patterns. They hide in logic, emerge across functions, and depend on control flow, data flow, and assumptions about how code is actually used.
VulnLLM-R changes that.
It's the first specialized reasoning LLM for vulnerability detection—a model trained to think like a human security auditor, step by step, about how vulnerabilities actually arise. And it achieves this with just 7B parameters, making it practical for real-world security workflows.
VulnLLM-R represents a fundamental shift from classification to reasoning in AI-powered security. Instead of just labeling code as "vulnerable" or "safe," it explains why something is exploitable—exactly what developers need to fix issues quickly.
Introduction: Why VulnLLM-R Matters
At Rafter, we spend a lot of time evaluating security tooling—static analyzers, dependency scanners, fuzzers, and increasingly, LLM-based approaches. Most LLMs in this space fall into one of two buckets:
- Pattern matchers in disguise (LLMs that label code as vulnerable or not)
- General-purpose reasoning models that can reason, but aren't trained deeply on security-specific logic
VulnLLM-R is different.
It's the first model we've seen that:
- Is explicitly trained for security reasoning
- Produces structured, explainable analyses
- Achieves strong results with just 7B parameters
- Scales from function-level analysis to repo-level agent workflows
In this post, we'll walk through:
- What VulnLLM-R actually is and how it works
- Why "reasoning" fundamentally changes vulnerability detection
- How the model is trained (in plain English)
- How to run it yourself
- Where it fits alongside tools like CodeQL and traditional static analyzers
What Is VulnLLM-R (And What "Reasoning" Really Means)
At its core, VulnLLM-R is a specialized reasoning LLM for vulnerability detection, introduced in the paper:
VulnLLM-R: A Specialized Reasoning LLM for Vulnerability Detection (arXiv:2512.07533)
Instead of treating vulnerability detection as a classification task ("vulnerable" vs "safe"), VulnLLM-R is trained to reason step by step about code behavior.
Pattern Matching vs Security Reasoning
Most traditional tools—and many LLM-based ones—operate like this:
- Identify a risky API or sink
- Look for a missing sanitizer or guard
- Flag the finding
That works well for simple cases. But consider scenarios like:
- Sanitization that depends on runtime conditions
- Security checks hidden behind feature flags
- Invariants enforced implicitly across modules
- Exploitability that depends on a specific call order
These are logic vulnerabilities, and they require reasoning. This is especially true for AI-generated code, where subtle security flaws can slip through even when the code looks correct.
VulnLLM-R explicitly models:
- Data flow (where inputs come from and where they end up)
- Control flow (which paths are reachable, and when)
- Security context (assumptions about trust boundaries and invariants)
The result isn't just a verdict—it's an explanation.
What the Model Produces
A typical VulnLLM-R output includes:
- The likely CWE class (Common Weakness Enumeration)
- The unsafe execution path (step-by-step trace)
- Why that path is exploitable in practice
- Suggested mitigations or safer patterns
This is exactly what developers and security engineers need to act on a finding. Instead of spending hours debugging why a scanner flagged something, you get an immediate explanation of the exploit path.
In production, you don't have to surface raw chain-of-thought. You can safely summarize the reasoning while preserving the actionable insight. The key is that the model has reasoned through the vulnerability, even if you present a condensed version to developers.
Why VulnLLM-R Is a Big Deal
There are three reasons this work stands out.
1. Strong Results with a Small Model
VulnLLM-R is a 7B parameter model—orders of magnitude smaller than frontier reasoning models like GPT-4 or Claude.
Despite that, the authors show that it:
- Matches or outperforms larger, general-purpose models
- Competes with established tools on vulnerability benchmarks
- Runs fast enough to be practical in real pipelines
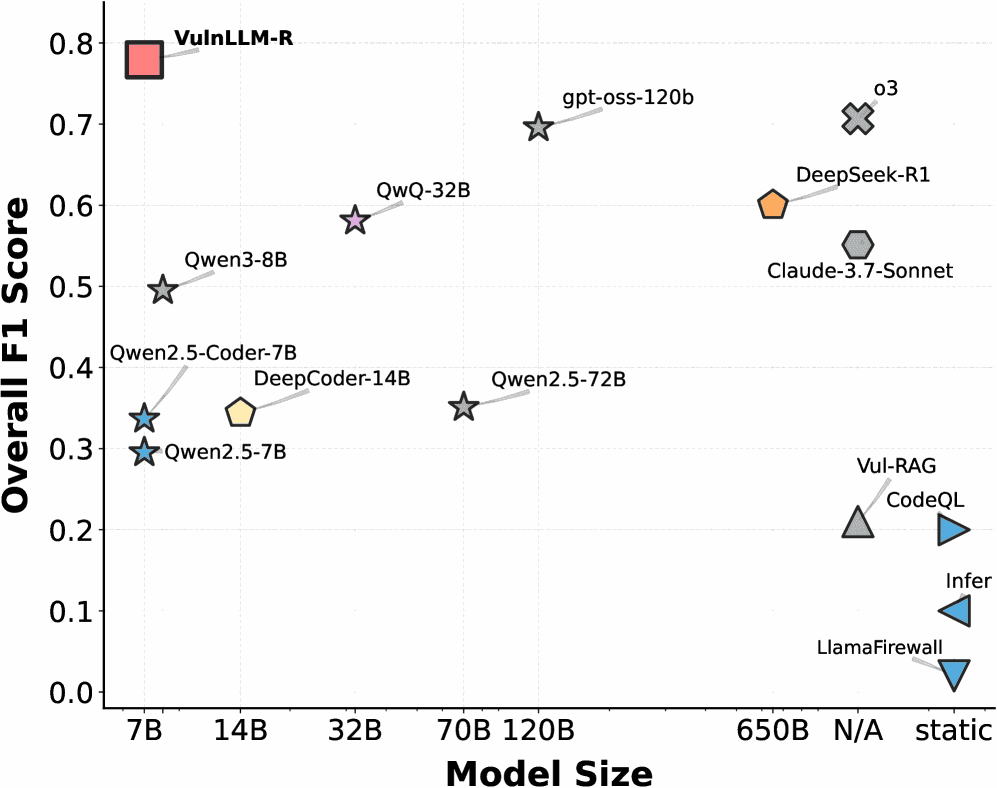
This matters because smaller models:
- Are cheaper to run (critical for CI/CD integration)
- Can be self-hosted (important for sensitive codebases)
- Fit naturally into security workflows without massive infrastructure
Security teams don't need another massive black box—they need something reliable and inspectable.
2. It's Evaluated as a System, Not Just a Model
One of the most impressive parts of the work is that VulnLLM-R isn't evaluated in isolation.
The authors introduce an agent-based scaffold that:
- Selects relevant files and functions
- Builds focused context windows
- Iteratively refines its analysis
- Applies testing-phase optimization to improve results
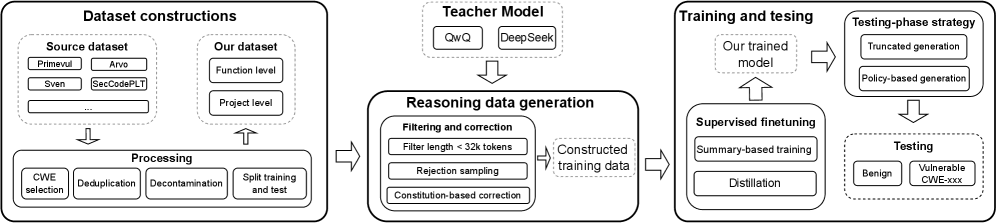
This is crucial. Vulnerabilities don't live in single functions—they live in repositories. A function might look safe in isolation, but become exploitable when called with specific inputs or in certain contexts.
In their evaluations, this agent-based approach outperforms traditional static analyzers in identifying real-world vulnerabilities—including previously undisclosed issues.
3. It Reframes How We Think About AI in Security
Most "AI security tools" ask:
Can an LLM replace a scanner?
VulnLLM-R asks a better question:
Can an LLM reason like a security engineer?
That shift—from classification to reasoning—is what makes this work durable. It's not trying to replace traditional static analysis. It's trying to augment it with human-like reasoning about exploitability.
How VulnLLM-R Is Built (Without the Hype)
Let's demystify the training pipeline.
Step 1: Security-Shaped Data
Not all vulnerability datasets teach reasoning. The authors carefully merge and curate datasets that include:
- Real vulnerabilities (not just synthetic examples)
- Non-trivial control and data flow (the kind that trips up pattern matchers)
- Hard negative examples (code that looks vulnerable but isn't)
They explicitly separate clean and noisy subsets to control for shortcut learning—ensuring the model learns actual security reasoning, not just pattern matching.
Step 2: Reasoning Data Generation and Filtering
The key insight: labels aren't enough.
The team generates step-by-step vulnerability analyses, then:
- Filters out shallow or incorrect reasoning
- Corrects flawed chains
- Prefers explanations that align with actual exploitability
This trains the model not just to answer—but to think correctly. It's the difference between memorizing that "SQL injection happens when you concatenate strings" and understanding why that's dangerous in specific contexts.
Step 3: Training (High Level)
The model is trained using:
- Supervised fine-tuning (SFT) to learn structured security reasoning
- Preference optimization to favor higher-quality analyses
You don't need to be an ML researcher to appreciate the result: a model that consistently explains why something is vulnerable, not just that it's vulnerable.
Running VulnLLM-R Yourself
One of the best parts: this work is reproducible.
The authors provide code, data, and scripts to run VulnLLM-R locally using modern inference stacks like vLLM.
Practical Ways to Use It
We see three immediate integration patterns:
-
Second-opinion analysis Run VulnLLM-R on high-risk or ambiguous findings from tools like CodeQL, Semgrep, or Rafter. When a scanner flags something but you can't see why it's exploitable, VulnLLM-R can provide the reasoning.
-
Reasoning explainer Take existing findings and generate human-readable exploit-path explanations for developers. This is especially valuable for AI-generated code, where developers might not understand why a pattern is dangerous.
-
Repo-level agent Use the full agent scaffold to explore a repository and surface novel logic bugs that traditional scanners miss.
At Rafter, we're especially excited about #1 and #2—augmenting existing scanners with reasoning, not replacing them.
Production Considerations
If you're deploying something like this:
- Prefer local inference for sensitive code (don't send proprietary code to external APIs)
- Store minimal context (only what's needed for reasoning)
- Summarize reasoning in reports (developers don't need the full chain-of-thought)
- Always keep a human in the loop for critical issues
LLMs amplify security teams—they don't replace judgment. This is especially important when dealing with critical vulnerabilities that could impact production systems.
For teams using automated security scanning, reasoning models like VulnLLM-R can significantly improve triage efficiency. Instead of manually investigating every finding, you get immediate explanations of exploitability.
Where VulnLLM-R Fits in the Security Landscape
It's important to be clear-eyed about tradeoffs.
What Classic Tools Still Do Best
Traditional static analyzers excel at:
- Deterministic rules (consistent results for well-defined patterns)
- Low false positives for common vulnerabilities like SQL injection or API key leaks
- Policy enforcement at scale (checking thousands of repos quickly)
These tools aren't going away. They're fast, reliable, and catch the majority of vulnerabilities.
What Reasoning Models Add
Reasoning models like VulnLLM-R excel at:
- Detection of logic vulnerabilities (bugs that require understanding control flow)
- Better triage and explanation (helping developers understand findings)
- Insight into exploitability (not just presence, but actual risk)
The Right Mental Model
VulnLLM-R isn't a silver bullet. It's a force multiplier—especially when paired with traditional scanners.
The ideal security stack combines:
- Fast pattern matchers for common vulnerabilities (automated scanning)
- Reasoning models for complex logic bugs (VulnLLM-R)
- Human expertise for critical decisions and novel attack patterns
That's exactly the direction we think security tooling should go. At Rafter, we're exploring how reasoning-based models can complement our existing scanners and improve developer experience.
Conclusion: Why We're Impressed
VulnLLM-R represents a genuine shift in how AI can be applied to security:
- It treats vulnerability detection as a reasoning problem, not just classification
- It shows that small, specialized models can outperform giants (7B parameters vs 100B+)
- It evaluates the system, not just the model (agent workflows matter)
- It produces outputs developers can actually use (explainable, actionable findings)
If you care about building secure software—and doing it without slowing teams down—this is work worth paying attention to.
The future of security tooling isn't about replacing scanners with AI. It's about combining the speed of pattern matching with the depth of reasoning. VulnLLM-R is a step in that direction.
At Rafter, we're actively exploring how reasoning-based models like VulnLLM-R can complement our existing scanners and improve developer experience. If that's interesting to you, stay tuned—and run a scan to see how traditional static analysis catches the obvious issues, while reasoning models help explain the subtle ones.
Related Resources
- Security Tool Comparisons: Choosing the Right Scanner
- When LLMs Write Code: Trusting Untrusted Outputs
- Securing AI-Generated Code: Best Practices
- Vulnerabilities Crash Course: Understanding Security Flaws
Want to see how reasoning-based vulnerability detection compares to traditional static analysis? Try Rafter to scan your codebase and get actionable security findings with clear explanations.